Tutto quello che vorresti sapere prima di installare.
Uno sguardo dettagliato su come funziona Rilevatore di Topic Cluster, perché l'abbiamo progettato così, e il ragionamento dietro le funzionalità qui sopra.
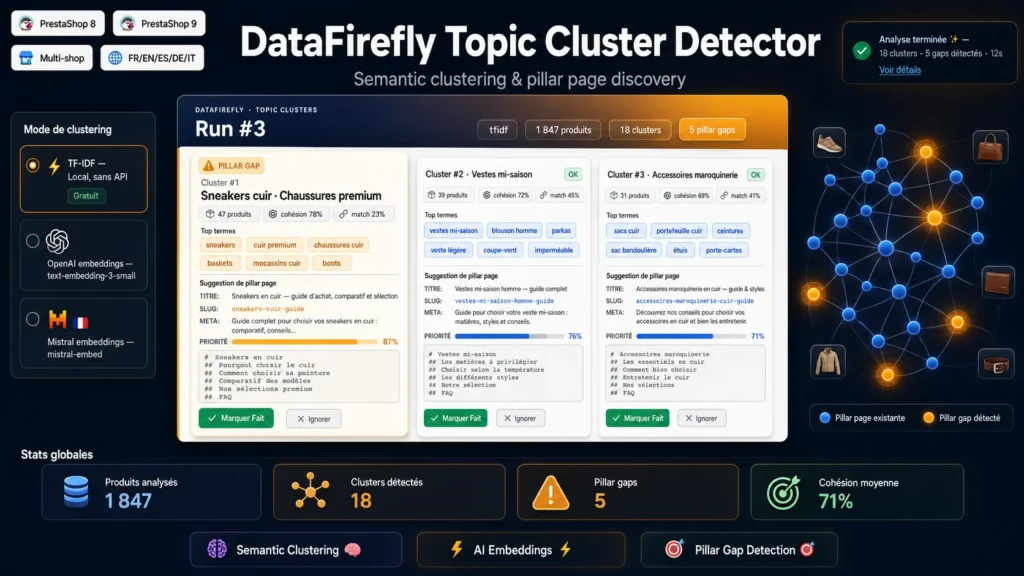
Perché un Rilevatore di Topic Cluster?
Il vostro catalogo è una miniera d'oro semantica spesso inesplorata. I vostri prodotti formano naturalmente raggruppamenti tematici che i motori di ricerca cercano di comprendere. Senza una pillar page-madre strutturante per ogni cluster, Google fatica a identificare la vostra competenza sull'argomento, e le vostre pagine prodotto si cannibalizzano a vicenda sulle query informazionali. Il Rilevatore di Topic Cluster identifica queste opportunità automaticamente.
Come funziona il clustering semantico?
Il modulo estrae per ogni prodotto un testo ponderato (nome triplo peso, meta doppio, categorie doppio, descrizione singola), lo tokenizza con stop-words per lingua, lo vettorizza in TF-IDF o in embeddings densi, normalizza i vettori in L2, e applica un k-means sferico con inizializzazione k-means++. I cluster emergono dalle vere similarità semantiche, non dal vostro albero di categorie.
Quale modalità scegliere: TF-IDF o embeddings?
Il TF-IDF è gratuito, istantaneo, senza chiamata API, ed eccellente per cataloghi lessicalmente omogenei (un dominio, un vocabolario). Gli embeddings OpenAI o Mistral catturano una semantica più ricca, comprendono sinonimi e varianti lessicali, ed eccellono su cataloghi diversificati o con descrizioni narrative. Potete testare entrambi e confrontare.
Come vengono rilevate le pillar page mancanti?
Il modulo recupera le vostre pagine CMS pubblicate e le vostre landing page di categoria (con descrizioni). Per ogni cluster, calcola un punteggio di match fuzzy tra i top-termini del cluster e i contenuti esistenti (titolo peso 1.0, meta 0.5, body 0.2). Sotto la soglia configurata (0.45 per default), il cluster è contrassegnato come pillar gap: avete la materia prodotto ma non la pagina-madre strutturante.
Cosa contiene la bozza generata per ogni gap?
Per ogni pillar page mancante, il modulo genera un titolo H1, uno slug URL-safe, una meta descrizione, un piano H2 completo in markdown (introduzione, cosa è, come scegliere, comparativa, migliori prodotti, casi d'uso, errori da evitare, FAQ, CTA), una lista di parole chiave target e un punteggio di priorità che combina dimensione del cluster e coesione semantica.
A chi si rivolge questo modulo?
Agli e-commerce che investono nel SEO long-tail, ai responsabili contenuto incaricati di strategie pillar/cluster, ai consulenti SEO in missione di audit, ai brand con grandi cataloghi mal coperti editorialmente. Il modulo è anche uno strumento diagnostico per identificare sovrapposizioni di categorie o opportunità di linking interno.
Ancora non ci sono recensioni.