Tout ce que vous voudriez savoir avant d'installer.
Un regard détaillé sur le fonctionnement de Détecteur de Topic Clusters, pourquoi nous l'avons conçu ainsi, et la réflexion derrière les fonctionnalités ci-dessus.
Pourquoi un Détecteur de Topic Clusters ?
Votre catalogue est une mine d'or sémantique souvent inexploitée. Vos produits forment naturellement des regroupements thématiques que les moteurs de recherche cherchent à comprendre. Sans pillar page-mère structurante pour chaque cluster, Google peine à identifier votre expertise sur le sujet, et vos pages produits se cannibalisent mutuellement sur les requêtes informationnelles. Le Détecteur de Topic Clusters identifie ces opportunités automatiquement.
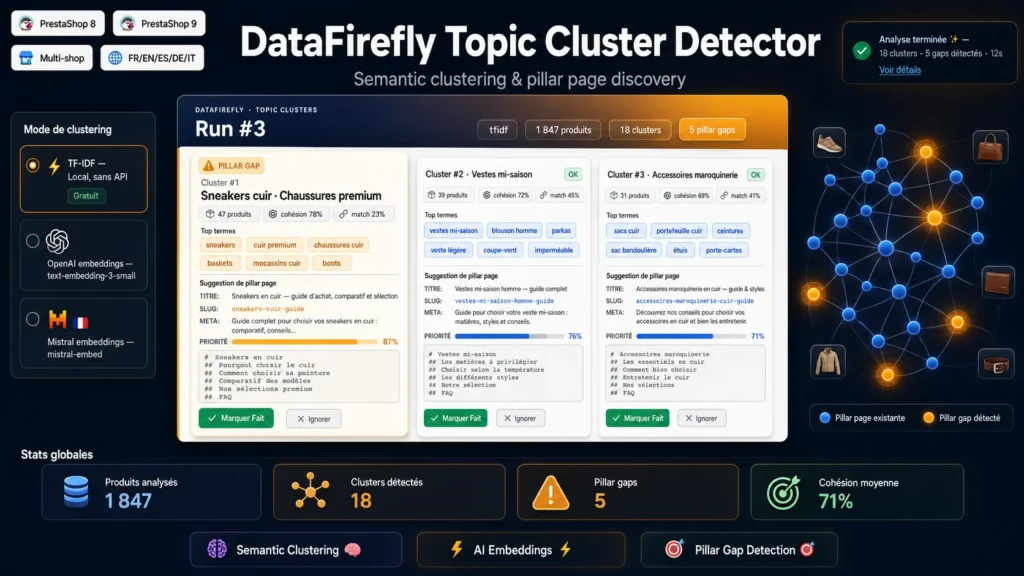
Comment fonctionne le clustering sémantique ?
Le module extrait pour chaque produit un texte pondéré (nom triple poids, meta double, catégories double, description simple), le tokenise avec stop-words par langue, le vectorise en TF-IDF ou en embeddings denses, normalise les vecteurs en L2, puis applique un k-means sphérique avec initialisation k-means++. Les clusters émergent des vraies similarités sémantiques, pas de votre arborescence de catégories.
Quel mode choisir : TF-IDF ou embeddings ?
Le TF-IDF est gratuit, instantané, sans appel API, et excellent pour les catalogues lexicalement homogènes (un domaine, un vocabulaire). Les embeddings OpenAI ou Mistral capturent une sémantique plus riche, comprennent les synonymes et les variantes lexicales, et excellent sur les catalogues diversifiés ou aux descriptions narratives. Vous pouvez tester les deux et comparer.
Comment sont détectées les pillar pages manquantes ?
Le module récupère vos pages CMS publiées et vos landing pages catégorie (avec descriptions). Pour chaque cluster, il calcule un score de match fuzzy entre les top-termes du cluster et les contenus existants (titre poids 1.0, méta 0.5, body 0.2). En dessous du seuil configuré (0.45 par défaut), le cluster est marqué pillar gap : vous avez la matière produit mais pas la page-mère structurante.
Que contient le brouillon généré pour chaque gap ?
Pour chaque pillar page manquante, le module génère un titre H1, un slug URL-safe, une méta description, un plan H2 complet en markdown (introduction, qu'est-ce que, comment choisir, comparatif, meilleurs produits, cas d'usage, erreurs à éviter, FAQ, CTA), une liste de mots-clés cibles et un score de priorité combinant taille du cluster et cohésion sémantique.
À qui ce module s'adresse-t-il ?
Aux e-commerçants qui investissent dans le SEO long-tail, aux responsables contenu en charge de stratégies pillar/cluster, aux consultants SEO en mission d'audit, aux marques avec un large catalogue mal couvert éditorialement. Le module est aussi un outil de diagnostic pour identifier les chevauchements de catégories ou les opportunités de maillage interne.
Il n’y a pas encore d’avis.