Tout ce que vous voudriez savoir avant d'installer.
Un regard détaillé sur le fonctionnement de Thin Content Detector — Détection IA contenu pauvre PrestaShop 8/9, pourquoi nous l'avons conçu ainsi, et la réflexion derrière les fonctionnalités ci-dessus.
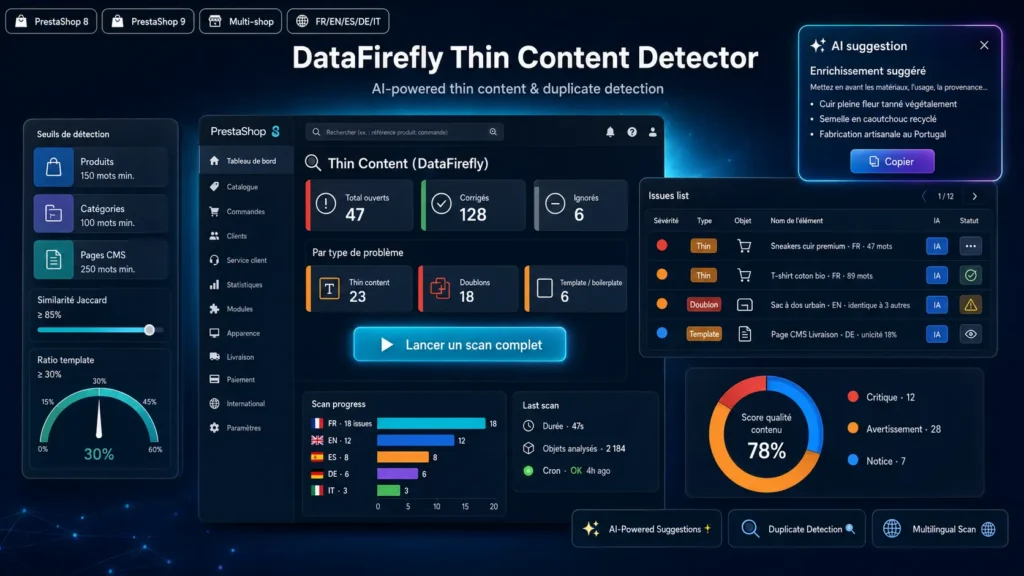
Pourquoi le thin content tue votre SEO
Depuis le Helpful Content Update, Google déclasse activement les pages au contenu trop pauvre, trop similaire ou trop dominé par des éléments répétés. Sur une boutique e-commerce, ce sont typiquement les fiches produit reprises du fournisseur, les catégories avec deux phrases génériques, ou les variantes qui partagent 95% de leur description. Invisible à l'œil nu sur un catalogue de 500 produits — mais cumulé, c'est ce qui empêche votre site de ranker.
Trois types de détection complémentaires
Thin Content Detector ne se contente pas de compter les mots. L'analyseur de contenu pauvre signale les pages sous le seuil. Le détecteur de doublons utilise un hash SHA1 pour les doublons exacts, puis une similarité Jaccard pour les quasi-doublons. L'analyseur de ratio template identifie les tokens qui apparaissent dans plus de la moitié des pages sœurs (même catégorie parent) et calcule le pourcentage de tokens uniques par page. Une page avec 200 mots mais 90% de boilerplate est tout aussi toxique qu'une page de 30 mots.
Suggestions IA contextualisées
Pour chaque problème détecté, le module génère une suggestion d'enrichissement via un endpoint compatible OpenAI. Le prompt est adapté au type de problème (enrichir le thin content, différencier les doublons, rendre unique le contenu trop template) ET au type d'objet (USP et specs pour les produits, USP de gamme pour les catégories, développement éditorial pour les CMS). Le retour est du HTML propre — paragraphes, listes, sous-titres — directement collable dans TinyMCE. Pas de markdown à nettoyer.
Endpoint IA agnostique
Configurez n'importe quel service compatible avec l'API chat completions OpenAI : OpenAI direct, Mistral AI, Groq pour des réponses ultra-rapides, Ollama en local pour zéro coût de tokens, ou Anthropic via un proxy compatible. Vous restez maître du fournisseur, du modèle et du coût.
Conçu pour les gros catalogues
Toutes les requêtes SQL sont chunkées (500 produits par batch). L'export CSV est streamé en sortie pour éviter la saturation mémoire. La détection de doublons utilise un pré-filtrage par nombre de mots (±50%) avant de calculer la similarité Jaccard, et un plafond de sécurité à 1500 items empêche toute complexité O(n²) catastrophique. Sur un catalogue de 5000 produits, un scan complet prend quelques minutes.
Cron sécurisé et auto-rescan
Un endpoint cron sécurisé par token vous permet de planifier les scans nocturnes via crontab. Activez le rescan automatique pour que chaque sauvegarde de produit, catégorie ou page CMS déclenche un re-test ciblé — vous voyez en temps réel si votre réécriture suffit à dépasser les seuils.
Il n’y a pas encore d’avis.