Everything you'd want to know before you install.
A detailed look at how Thin Content Detector — AI Thin Content Detection for PrestaShop 8/9 works, why we built it the way we did, and the thinking behind the features above.
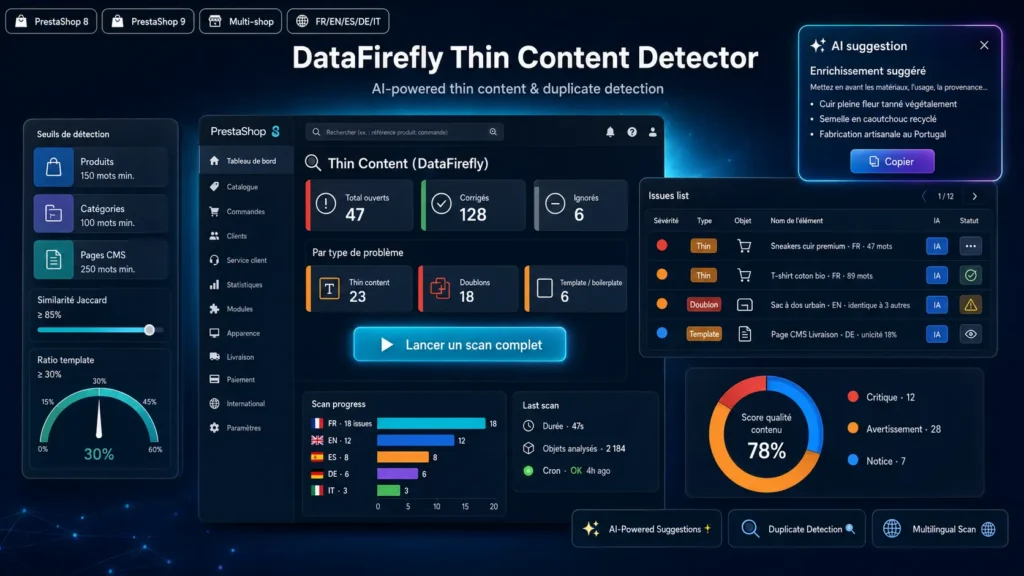
Why thin content kills your SEO
Since the Helpful Content Update, Google has been actively demoting pages with content that's too thin, too similar, or too dominated by repeated elements. On an e-commerce shop, that's typically product sheets copied from the supplier, categories with two generic sentences, or variants sharing 95% of their description. Invisible to the naked eye on a catalogue of 500 products — but cumulatively, it's what stops your site from ranking.
Three complementary detection types
Thin Content Detector doesn't just count words. The content analyser flags pages below the threshold. The duplicate detector uses a SHA1 hash for exact duplicates, then a Jaccard similarity for near-duplicates. The template ratio analyser identifies tokens that appear in more than half of the sibling pages (same parent category) and calculates the percentage of unique tokens per page. A page with 200 words but 90% boilerplate is just as toxic as a 30-word page.
Context-aware AI suggestions
For each detected issue, the module generates an enrichment suggestion via an OpenAI-compatible endpoint. The prompt is tailored to the issue type (enrich thin content, differentiate duplicates, make template-heavy content unique) AND to the object type (USPs and specs for products, range USPs for categories, editorial development for CMS). The output is clean HTML — paragraphs, lists, subheadings — directly pasteable into TinyMCE. No markdown to clean up.
Provider-agnostic AI endpoint
Configure any service compatible with the OpenAI chat completions API: OpenAI direct, Mistral AI, Groq for ultra-fast responses, local Ollama for zero token cost, or Anthropic through a compatible proxy. You stay in control of the provider, model and cost.
Designed for large catalogues
All SQL queries are chunked (500 products per batch). CSV export is streamed to output to avoid memory saturation. Duplicate detection uses pre-filtering by word count (±50%) before computing Jaccard similarity, and a safety cap at 1500 items prevents any catastrophic O(n²) complexity. On a 5000-product catalogue, a full scan takes a few minutes.
Secure cron and auto-rescan
A token-protected cron endpoint lets you schedule nightly scans via crontab. Enable automatic rescan so every save of a product, category or CMS page triggers a targeted re-test — you see in real time whether your rewrite is enough to clear the thresholds.
There are no reviews yet.