Todo lo que querrías saber antes de instalar.
Una mirada detallada a cómo funciona Thin Content Detector — Detección IA contenido pobre PrestaShop 8/9, por qué lo construimos así y la lógica detrás de las características anteriores.
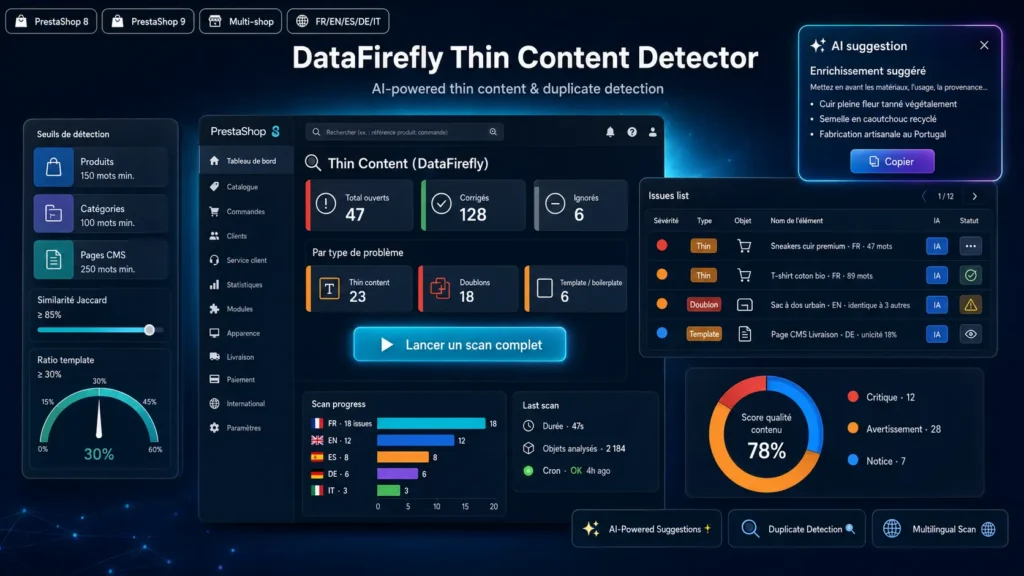
Por qué el thin content arruina tu SEO
Desde el Helpful Content Update, Google está degradando activamente las páginas con contenido demasiado pobre, demasiado similar o demasiado dominado por elementos repetidos. En una tienda e-commerce, suelen ser fichas de producto copiadas del proveedor, categorías con dos frases genéricas o variantes que comparten el 95% de su descripción. Invisible a simple vista en un catálogo de 500 productos, pero acumulado es lo que impide que tu sitio posicione.
Tres tipos de detección complementarios
Thin Content Detector no se limita a contar palabras. El analizador de contenido pobre señala las páginas por debajo del umbral. El detector de duplicados usa un hash SHA1 para los duplicados exactos, después una similitud Jaccard para los cuasi-duplicados. El analizador de ratio plantilla identifica los tokens que aparecen en más de la mitad de las páginas hermanas (misma categoría padre) y calcula el porcentaje de tokens únicos por página. Una página con 200 palabras pero 90% de boilerplate es tan tóxica como una página de 30 palabras.
Sugerencias IA contextualizadas
Para cada problema detectado, el módulo genera una sugerencia de enriquecimiento mediante un endpoint compatible con OpenAI. El prompt está adaptado al tipo de problema (enriquecer thin content, diferenciar duplicados, hacer único contenido demasiado plantilla) Y al tipo de objeto (USPs y specs para productos, USPs de gama para categorías, desarrollo editorial para CMS). El resultado es HTML limpio (párrafos, listas, subtítulos), directamente pegable en TinyMCE. Sin markdown que limpiar.
Endpoint IA agnóstico
Configura cualquier servicio compatible con la API chat completions de OpenAI: OpenAI directo, Mistral AI, Groq para respuestas ultra-rápidas, Ollama en local para coste cero de tokens, o Anthropic vía proxy compatible. Mantienes el control del proveedor, modelo y coste.
Diseñado para grandes catálogos
Todas las consultas SQL están en lotes (500 productos por batch). La exportación CSV se transmite en streaming para evitar la saturación de memoria. La detección de duplicados utiliza un pre-filtrado por número de palabras (±50%) antes de calcular la similitud Jaccard, y un tope de seguridad de 1500 elementos impide cualquier complejidad O(n²) catastrófica. En un catálogo de 5000 productos, un escaneo completo dura unos minutos.
Cron seguro y reescaneo automático
Un endpoint cron protegido por token te permite programar escaneos nocturnos mediante crontab. Activa el reescaneo automático para que cada guardado de producto, categoría o página CMS desencadene un retest dirigido — verás en tiempo real si tu reescritura supera los umbrales.
No hay valoraciones aún.