Alles, was Sie wissen sollten bevor Sie installieren.
Ein detaillierter Blick darauf, wie Thin Content Detector — KI Thin-Content-Erkennung PrestaShop 8/9 funktioniert, warum wir es so gebaut haben und der Gedanke hinter den Funktionen oben.
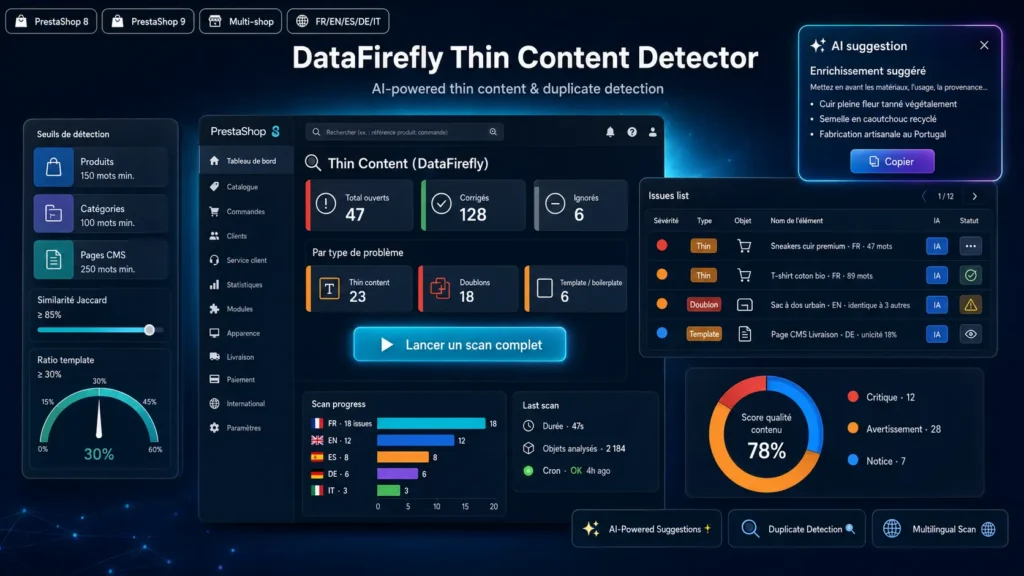
Warum Thin Content Ihr SEO ruiniert
Seit dem Helpful Content Update stuft Google aktiv Seiten ab, deren Inhalt zu dünn, zu ähnlich oder zu sehr von wiederholten Elementen dominiert wird. In einem E-Commerce-Shop sind das typischerweise vom Lieferanten kopierte Produktblätter, Kategorien mit zwei generischen Sätzen oder Varianten, die 95% ihrer Beschreibung teilen. Für das bloße Auge unsichtbar bei einem Katalog mit 500 Produkten — aber kumuliert ist es das, was Ihre Website am Ranking hindert.
Drei sich ergänzende Erkennungstypen
Thin Content Detector zählt nicht nur Wörter. Der Inhaltsanalysator markiert Seiten unterhalb der Schwelle. Der Duplikatdetektor verwendet einen SHA1-Hash für exakte Duplikate, dann eine Jaccard-Ähnlichkeit für Quasi-Duplikate. Der Template-Ratio-Analysator identifiziert Tokens, die in mehr als der Hälfte der Geschwisterseiten (gleiche übergeordnete Kategorie) erscheinen, und berechnet den Prozentsatz eindeutiger Tokens pro Seite. Eine Seite mit 200 Wörtern, aber 90% Boilerplate ist genauso toxisch wie eine Seite mit 30 Wörtern.
Kontextbezogene KI-Vorschläge
Für jedes erkannte Problem generiert das Modul einen Anreicherungsvorschlag über einen OpenAI-kompatiblen Endpunkt. Der Prompt ist auf den Problemtyp (Thin Content anreichern, Duplikate differenzieren, zu Template-lastigen Inhalt einzigartig machen) UND auf den Objekttyp (USPs und Specs für Produkte, Sortiments-USPs für Kategorien, redaktionelle Entwicklung für CMS) zugeschnitten. Das Ergebnis ist sauberes HTML — Absätze, Listen, Zwischenüberschriften — direkt in TinyMCE einfügbar. Kein Markdown zum Bereinigen.
Anbieter-unabhängiger KI-Endpunkt
Konfigurieren Sie jeden Dienst, der mit der OpenAI Chat Completions API kompatibel ist: OpenAI direkt, Mistral AI, Groq für ultraschnelle Antworten, lokales Ollama für Null Token-Kosten oder Anthropic über einen kompatiblen Proxy. Sie behalten die Kontrolle über Anbieter, Modell und Kosten.
Für große Kataloge ausgelegt
Alle SQL-Abfragen sind in Batches aufgeteilt (500 Produkte pro Batch). Der CSV-Export wird gestreamt, um eine Speichersättigung zu vermeiden. Die Duplikaterkennung verwendet eine Vorfilterung nach Wortzahl (±50%) vor der Berechnung der Jaccard-Ähnlichkeit, und eine Sicherheitsobergrenze bei 1500 Elementen verhindert jede katastrophale O(n²)-Komplexität. Bei einem 5000-Produkte-Katalog dauert ein vollständiger Scan einige Minuten.
Sicherer Cron und automatischer erneuter Scan
Ein token-geschützter Cron-Endpunkt ermöglicht es Ihnen, nächtliche Scans über crontab zu planen. Aktivieren Sie den automatischen erneuten Scan, sodass jedes Speichern eines Produkts, einer Kategorie oder einer CMS-Seite einen gezielten erneuten Test auslöst — Sie sehen in Echtzeit, ob Ihre Umschreibung ausreicht, um die Schwellenwerte zu überschreiten.
Es gibt noch keine Rezensionen.