Tutto quello che vorresti sapere prima di installare.
Uno sguardo dettagliato su come funziona Thin Content Detector — Rilevamento IA contenuto povero PrestaShop 8/9, perché l'abbiamo progettato così, e il ragionamento dietro le funzionalità qui sopra.
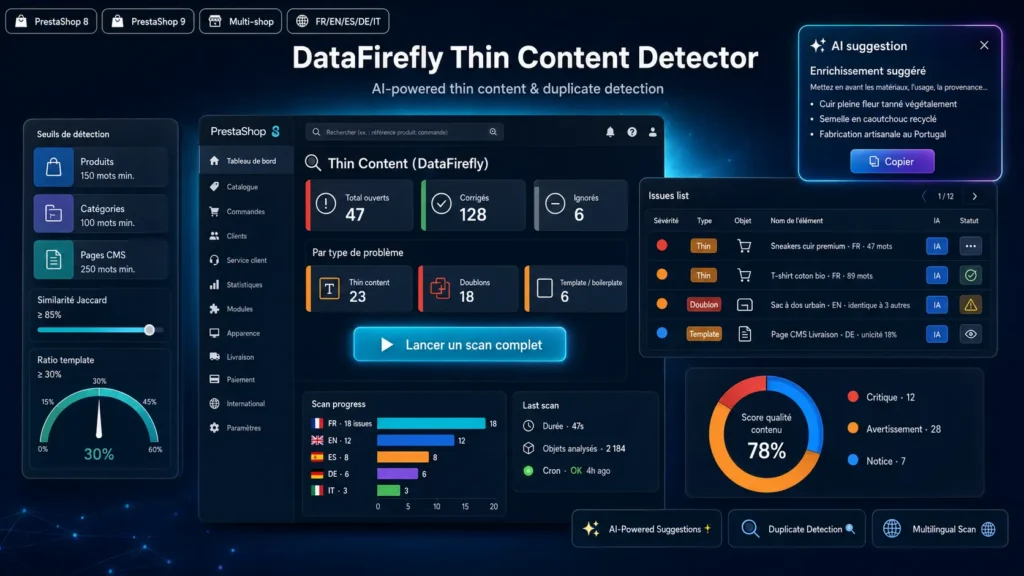
Perché il thin content uccide la tua SEO
Dal Helpful Content Update, Google sta retrocedendo attivamente le pagine con contenuti troppo poveri, troppo simili o troppo dominati da elementi ripetuti. In un negozio e-commerce, sono tipicamente le schede prodotto copiate dal fornitore, le categorie con due frasi generiche o le varianti che condividono il 95% della loro descrizione. Invisibile a occhio nudo su un catalogo di 500 prodotti — ma cumulato, è ciò che impedisce al tuo sito di posizionarsi.
Tre tipi di rilevamento complementari
Thin Content Detector non si limita a contare le parole. L'analizzatore di contenuto povero segnala le pagine sotto la soglia. Il rilevatore di duplicati utilizza un hash SHA1 per i duplicati esatti, poi una similarità Jaccard per i quasi-duplicati. L'analizzatore di rapporto template identifica i token che appaiono in più della metà delle pagine sorelle (stessa categoria padre) e calcola la percentuale di token unici per pagina. Una pagina con 200 parole ma 90% di boilerplate è tossica quanto una pagina di 30 parole.
Suggerimenti IA contestualizzati
Per ogni problema rilevato, il modulo genera un suggerimento di arricchimento tramite un endpoint compatibile con OpenAI. Il prompt è adattato al tipo di problema (arricchire thin content, differenziare duplicati, rendere unico contenuto troppo template) E al tipo di oggetto (USP e specifiche per i prodotti, USP di gamma per le categorie, sviluppo editoriale per il CMS). L'output è HTML pulito — paragrafi, liste, sottotitoli — direttamente incollabile in TinyMCE. Niente markdown da ripulire.
Endpoint IA agnostico
Configura qualsiasi servizio compatibile con l'API chat completions di OpenAI: OpenAI diretto, Mistral AI, Groq per risposte ultraveloci, Ollama in locale per costo zero di token, o Anthropic tramite proxy compatibile. Mantieni il controllo su provider, modello e costo.
Progettato per grandi cataloghi
Tutte le query SQL sono in batch (500 prodotti per batch). L'esportazione CSV è in streaming per evitare la saturazione di memoria. Il rilevamento di duplicati utilizza un pre-filtro per numero di parole (±50%) prima di calcolare la similarità Jaccard, e un tetto di sicurezza a 1500 elementi impedisce qualsiasi complessità O(n²) catastrofica. Su un catalogo di 5000 prodotti, una scansione completa dura alcuni minuti.
Cron sicuro e riscansione automatica
Un endpoint cron protetto da token ti permette di pianificare scansioni notturne tramite crontab. Attiva la riscansione automatica affinché ogni salvataggio di prodotto, categoria o pagina CMS attivi un retest mirato — vedrai in tempo reale se la tua riscrittura è sufficiente a superare le soglie.
Ancora non ci sono recensioni.